摘要:本文记录了一次真实的 FPGA 时序优化过程。在
NetBoost项目的 IP 分片重组模块中,遇到了一条 Slack 高达 -7.8ns、逻辑级数 49级 的恶性时序违例。通过“侦探式”的分析,我们锁定了**“组合逻辑环直接驱动复位端”这一元凶,并最终通过“后台寄存器预判 (Background Registered Look-ahead)”** 的架构级优化,成功解决了问题。本文将详细还原分析过程、方案对比及最终代码实现。
1. 案发:惊人的时序报告
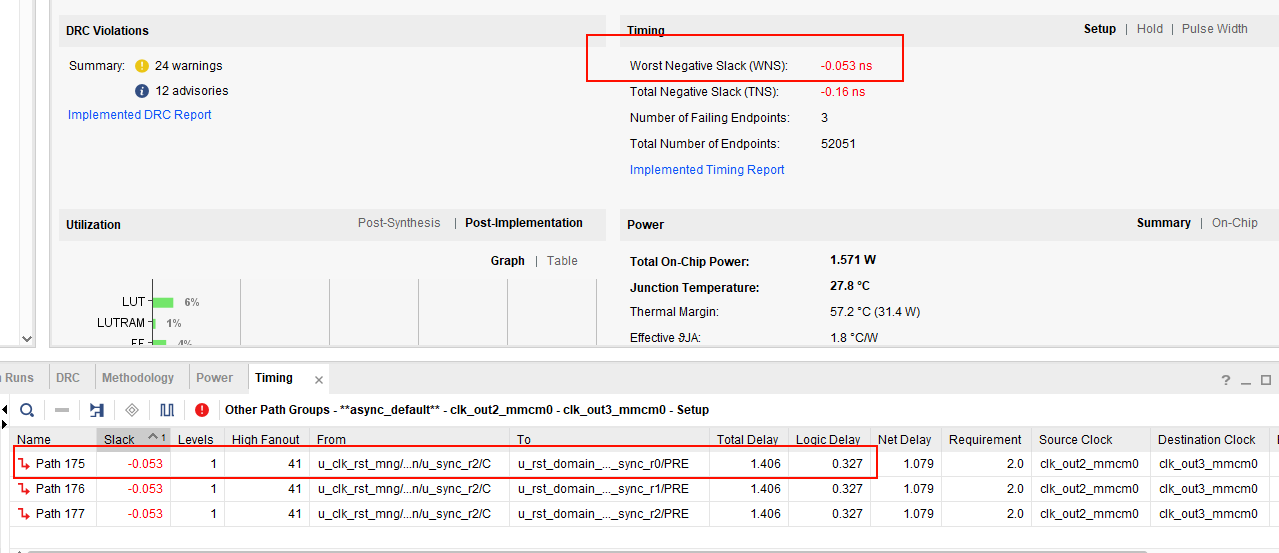
在对 NetBoost 工程进行综合实现后,时序报告发出红灯警报。打开时序分析报告,Header 部分的数据令人倒吸一口凉气:
- Slack:
<font color="red">-7.863 ns</font>(对于 100MHz/10ns 的时钟,这意味着实际路径跑了 ~18ns) - Logic Levels:
<font color="red">49</font>(通常 100MHz 逻辑级数应控制在 10~15 级以内) - Path Type: Setup (Max at Slow Process Corner)
这不是简单的“稍微优化一下”就能解决的问题,这是一次架构级的灾难。
2. 侦查:锁定元凶
像侦探破案一样,我们需要从报告中寻找蛛丝马迹。
2.1 路径追踪
查看报告的 Source (起点) 和 Destination (终点):
- Source:
SLOT_UPDATE[0].r_slot_status_reg(Slot 0 的状态寄存器) - Destination:
SLOT_UPDATE[3].r_slot_recv_bytes_reg/R(Slot 3 接收计数器的复位端)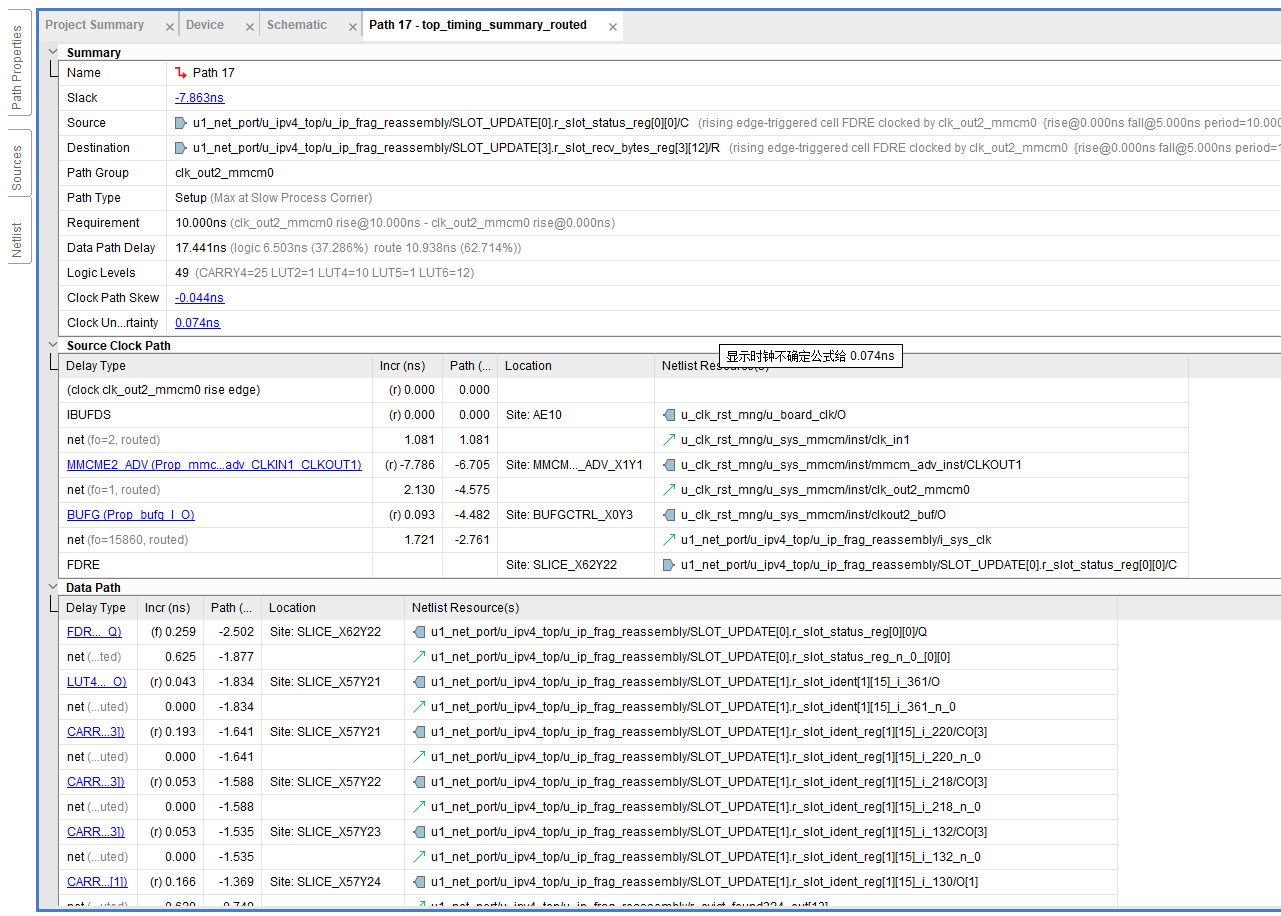
2.2 案情还原
这说明:“Slot 0 是不是空闲,决定了 Slot 3 要不要被清零。”
回到代码 ip_frag_reassembly.v,我们很快找到了对应的逻辑:
| |
完整的犯罪路径:
- 起点:
r_slot_status[0] - 过程:经过 8 级级联的组合逻辑判断 (Priority Encoder),算出
r_alloc_slot。 - 扇出:算出的结果直接驱动了 8 个 Slot 内部所有寄存器 的复位端 (Reset)。
- 终点:
r_slot_recv_bytes/R。
组合逻辑链太长(49级逻辑),且直接驱动高扇出的控制端(复位),导致了巨大的路由延迟和逻辑延迟。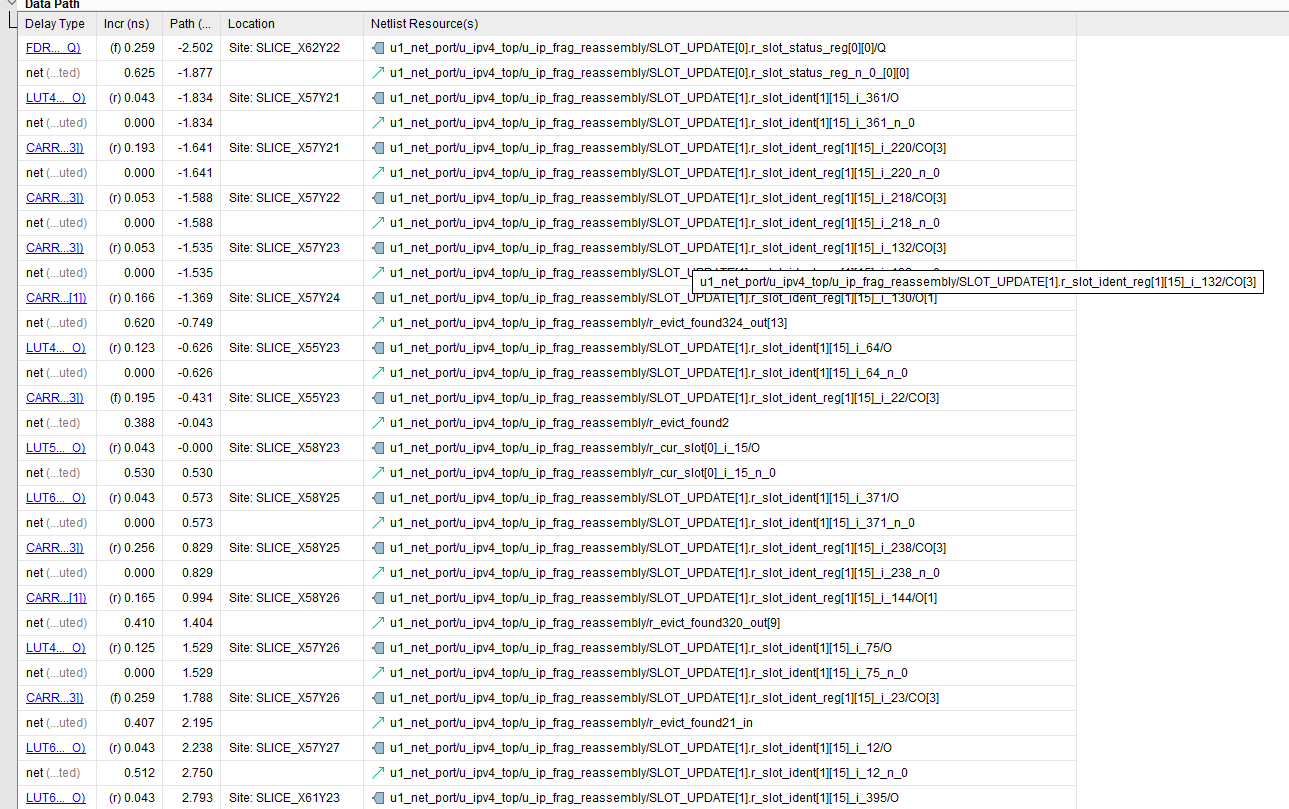
3. 深度解析:为什么会产生 49 级逻辑?
对于不熟悉 FPGA 底层结构的工程师来说,“49级逻辑"听起来可能有些抽象。让我们下潜到 Transistor 和 Slice 级别来看看发生了什么。
3.1 查找表 (LUT) 与进位链 (Carry Chain)
在 Xilinx 7-series FPGA 中,基本的逻辑单元是 LUT6 (6输入查找表)。
- LUT的物理限制:一个 LUT6 只能实现 6 个输入的任意布线逻辑。一旦变量超过 6 个(比如我们的 8 路 Priority Encoder,涉及 8 个 Status 位和无数中间变量),综合工具就必须把多个 LUT 级联起来。
- 链式效应:原代码中的
for循环虽然写起来像并行遍历,但由于!r_alloc_found这个信号的存在,实际上暗示了硬件必须先算 i=0,再算 i=1… 这是一个典型的串行依赖链。综合工具将其翻译成了一长串的 MUX(多路选择器)级联,导致信号像跑接力赛一样穿过几十个 LUT。
3.2 致命的控制集 (Control Set)
时序报告显示终点是 r_slot_recv_bytes_reg/R (复位端)。
- Control Set 延迟大:FPGA 的 Flip-Flop 控制端(Reset/Set/CE)通常比数据端(D)慢。
- 高扇出惩罚:计算出的
r_alloc_slot信号需要同时驱动 8个 Slot 对内的几十个寄存器的复位端。这被称为高扇出 (High Fanout) 网络。为了驱动这么多负载,布线工具必须在中间插入 Buffer 或进行网络复制,进一步增加了 “Route Delay”(在本次报告中占了 62% 之多)。
这就是为什么看似简单的 “找空闲” 逻辑,最终演变成了 49 级逻辑 + 7.8ns 的延迟。
4. 抉择:串行轮询 vs 并行打拍
如何打破这个长链?我有两个选择。这也是架构师经常面临的权衡。
方案 A:LRU 风格的串行轮询 (Serial Scanning)
在处理 LRU 驱逐逻辑时,我曾使用过这种方案:用一个计数器 cnt,每个周期只检查一个 Slot,耗时 8 个周期找完。
- 优点:逻辑极简,面积最小。
- 缺点:延迟大。写入侧的状态机需要停下来等 8 个周期才能拿到结果。对于 Slot 分配 这种位于主数据通路上的关键逻辑,这会降低吞吐量。
方案 B:后台寄存器预判 (Register Look-ahead) —— 本案采用
利用数据包传输的间隙,在后台时刻并行计算“下一个空闲的是谁”,并把结果存入寄存器。
- 优点:
- 零等待:FSM 需要分配时,直接取寄存器值,耗时为 0。
- 切断时序:
Status->组合逻辑->Register->Control Logic。路径被从中间完美的切开了。
| 方案 | 1. 组合逻辑暴力算 (原始) | 2. 串行轮询 (LRU) | 3. 后台寄存器预判 (最优) |
|---|---|---|---|
| 时序 | ❌ 崩盘 (-7.8ns) | ✅ 优秀 | ✅ 优秀 |
| 延迟 | 0 周期 | 1~8 周期 | 0 周期 (Look-ahead) |
| 适用 | 低速逻辑 | 后台非关键逻辑 | 高速关键路径 |
5. 实施:代码重构
我们删除了原有的 always @(*) 块,引入了新的寄存器 r_next_free_slot。
优化后的代码:
| |
同时,更新状态机和复位逻辑,直接使用 r_next_free_found 和 r_next_free_slot:
| |
6. 验证
修改代码,重新编译后,解决了刚才的时序违例问题,时序报告如下:
图中的时序违例从-7.8ns降低到0.053ns,说明优化成功。违例没有降到0ns,是因为其他模块有问题,可以通过本文介绍的分析方法再去优化。
7. 总结
这次优化展示了 FPGA 设计中解决 Setup Time Violation 的经典手段:Pipelining (流水线打拍)。
但单纯的打拍会增加延迟(Latency)。本例的精髓在于,我们不是在数据流中间硬塞一个拍子让数据变慢,而是在控制流的侧面由后台逻辑提前计算好结果(Look-ahead)。
核心心法:
- 算不过来就拆(像 LRU 那样拆成多周期)。
- 传不过去就存(像 Alloc 这样存入寄存器切断路径)。
- 不要让组合逻辑直接驱动高扇出的 Reset/Enable 端。
通过这次修改,我们将一个无法综合的时序灾难,变成了稳定可靠的高速逻辑,且没有牺牲任何业务吞吐量。
有些知识点再拓展说一下。
8. 为什么起点是 C,终点是 R?
这是初学者最常疑惑的一点。
- Source/C (Clock Pin):时序分析的起点永远是时钟击中源寄存器引脚的瞬间。数据从 C 到 Q (Output) 存在一个 $Tco$ 延迟,它是信号“起跑”的枪声。
- Destination/R (Reset Pin):在 Xilinx 7 系列的 FDRE(带使能与同步复位的触发器)原语中,
R引脚是一个同步控制端。 - 映射逻辑:我们在 RTL 中写下
if (do_evict) r_count <= 0;。为了节省 LUT 面积,Vivado 综合器会将“复杂的驱逐判定逻辑(evict)”直接驱动到寄存器的R端。也就是说,这 49 级逻辑延迟,全部花在了**决定“要不要复位计数器”**这件事上。
9. 微观底层:CARRY4 进位链的堆叠效应
报告中出现了 25 个 CARRY4 指令。这是理解本次违例的关键。
1. 1 CARRY4 = 4 Bits 的硬物理规则
在 Xilinx 7-Series 底层,一个 Slice 包含 4 个 LUT 和 1 个专用的进位链原语 CARRY4。
- 加法/减法/比较:底层都是通过进位链实现的。
- 计算公式:一个 16 位的减法器需要 $16 \div 4 = 4$ 个
CARRY4垂直级联。
2. for 循环的“罪恶”展开
我们在 RTL 中使用组合逻辑遍历 8 个 Slot 寻找最老时间戳:
| |
虽然代码看起来只有几行,但在综合后的电路图中,这演变成了 8 套减法器和比较器的串行拓扑。
- $8 \text{ Slot} \times (4 \text{ 级减法} + 4 \text{ 级比较}) = 64$ 级进位链潜力。
- Vivado 通过逻辑压缩优化到了 49 级,但这依然像是在硅片上筑起了一座信号无法逾越的长城。
10. 理论升华:静态时序分析(STA)的数学本质
Vivado 为什么要费心计算这些?它的核心公式揭示了时序优化的方向:
1. Setup Slack 的核心方程
$$ Slack = (T_{capture_edge} + T_{dest_clk_delay} - T_{setup}) - (T_{launch_edge} + T_{source_clk_delay} + T_{datapath}) $$
- 数据路径延迟 ($T_{datapath}$):就是那 17.441ns。它由逻辑延迟(Logic)和布线延迟(Route)组成。
- 悲观估计:Vivado 在 Slow Corner (最坏工艺角) 下进行 Setup 分析。在这个角落,温度最高、电压最低、晶体管开关最慢。如果信号在此条件下能跑通,那么在任何环境下都是安全的。
2. 逻辑级数与布线的恶性循环
当你的逻辑级数达到 49 级时,意味着信号必须穿过 49 个不同的物理门电路。在物理布局(Placement)时,由于这些元件必须排成一排以维持进位链连接,工具无法进行灵活布局。
这导致了报告中常见的现象:Route 延迟占比高达 63%。不是布线工具不努力,而是逻辑太长,导致它不得不跨越半个芯片去连接这些元件。
后记:高频 FPGA 设计的三条金律
- 进位链意识:在写
always @(*)时,脑子里要自带“比特计数计数器”。超过 32 位的加减比较,必须警惕逻辑级数。- 空间换时间/时间换路径:如果路径太长,要么用更多的面积做树状并行(Tree Comparator),要么多花几个周期做后台处理。
- 读懂 R/CE/D 映射:不要以为写了同步复位就万事大吉,它同样是时序增长的关键节点。